
Federated Learning
"pip install the-worlds-data"

This is not how I thought I’d begin this breakdown but.. Andrew Trask has been keeping me up at night.
Andrew has described an idyllic state where we can securely “pip install the-worlds-data” — ie give data scientists access to the world’s most sensitive data in a privacy-preserving, yet productive, way.
I know for some of you this may sound a tad dystopian. However, this is an end state that we should all be ** very excited ** about as more data == more problems that can be solved. It also means that those dreaded four-letter acronyms (no, not eBPF) (niche joke) GDPR et al., and their future derivatives, can continue to protect consumers without hindering progress.
Many privacy-enhancing technologies exist and are typically used in cryptographic concertation. Whilst we’ll focus on federated learning, we’ll foray into adjacent technologies such as differential privacy and secure aggregation which are
being used to bring federated learning further into production.
If you’re building tooling to bring federated learning further into production I’d love to talk to you / grab coffee if you’re in London » alex@tapestry.vc
Federated Learning Primer
Federated learning enables edge devices (e.g., your iPhone) to collaboratively train machine learning models while keeping the raw training data on each user’s device.
The individual “model parameters” produced by each device as they train their respective models are then aggregated to form one final shared model — a “global inference model”.
Technical Detail: To notably overgeneralize, machine learning is the process of using math to make predictions.
“Model parameters” are the variables that are tweaked within a machine learning mathematical function (aka a model) over time (ie through “training”) to increase the model’s prediction accuracy.
Thus we now have a way to enhance users’ privacy whilst simultaneously leveraging their data. ~Theoretically~ this will lead to the increased collection and utilization of sensitive data like biomarkers, personally identifiable images, speech, etc.
One step closer to pip install[ing] the-worlds-data.

Federated learning is easy to grok in principle. I figured we’d better humble ourselves a wee bit by delving deeper into our definition by honing in on two keywords: keeping and collaboratively.
1. Keeping
This containment of data within the device that generates it (remember, your iPhone) stands in stark contrast with the typical training approach in machine learning.
** I’m going to ramble here but the below is important for the “why now” section later **
Traditionally, models are trained “centrally”, meaning that the data used to train these models is created and then “loaded” into a central location (e.g., a data center). The model to be trained also lives in this central location and is trained here.
Why train centrally? The most salient reasons with respect to federated learning are centered around the constraints of training on edge devices vs. data centers:
Training can require a meaningful amount of compute — because training requires math and math requires compute! Compute can be far more plentiful in a data center full of powerful domain-specific servers vs. on your iPhone.
High compute usage (due to training) consumes battery life. As a consumer, I personally don’t want my battery to whittle down to 5% for the “greater good” of training a model (sorry Gboard).
Edge devices and the data they collect are heterogeneous. This is an issue as conventional machine learning wisdom assumes that “local” models (ie models on the edge device) need to have the same architecture as the global inference model.
** Now is a good time to revisit the diagram above with your newfound knowledge **
As I mentioned in my eBPF post (smooth backlink huh), constraints beget innovation. Federated learning acknowledges edge devices’ constraints and has conceived of novel methods to mitigate their impact:
Devices are selected for training only when they’re idle, charging, and connected to an ~unmetered network like Wi-Fi — reducing battery usage and cost concerns for the user.
Individual devices don’t share the entire model that they train. Instead, they send the model’s updated model parameters. This means that the amount of data communicated wirelessly is significantly less.
Individual model updates are “clipped” in order to reduce heterogeneous data/device’s impact (more on this later).
2. Collaboratively
Multiple edge devices need to collaborate with one another and a central server to form a global inference model. Why? Because if we relied on a model trained by one device it’d be “overfitted” to one device’s data, and hence, not generally useful for all devices.
Remember the central server I mentioned earlier? It comes into play to handle this coordination.
This coordination process begins with the selection of the machine learning model to be trained and initialized. Broadly speaking, “initialized” means configured (the detail isn’t important here).
** I’m aware this is turning into a Hadrian’s Wall of text - aesthetic diagram soon **
The central server then begins a series of interactions with edge devices known as federated learning rounds. Each federated learning round consists of the following steps:
Device Selection: a fraction of the total available edge devices are chosen to train the current global inference model on their “local” data. Why a fraction? Remember, devices only participate in federated learning if they’re idle, charging, etc.
Configuration: the selected devices are sent the current global inference model by the central server. They’re also told how to train the model (as there are many ways to train a model) via instructions known as a “federated learning plan”.
Training: each selected device trains the current global inference model based on the device’s local data.
Reporting: post-training the model, each device sends its updated model parameters to the central server for ✨ secure aggregation ✨ (we’ll come back to this in the next section).
Once a pre-defined termination criterion is met the process is terminated and a final global inference model exists. This criteri(on/a) could be an accuracy target, a certain number of federated learning rounds — use your intuition!
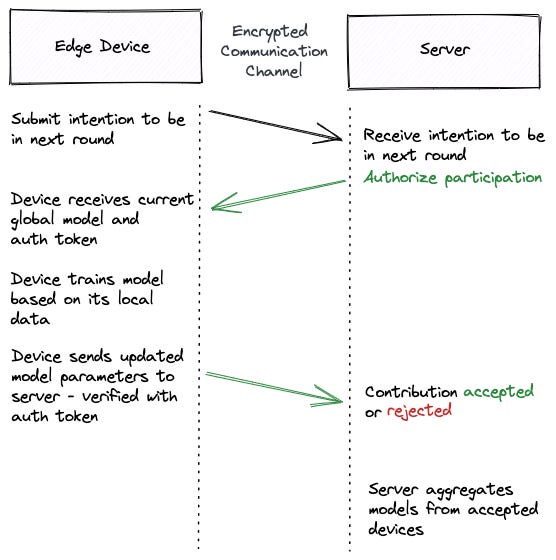
** If you’ve followed along this far (and if I’ve done my job correctly) you now understand how Federated Learning works **
Privacy-Enhancing Technologies
I tend to use ✨ star brackets ✨ facetiously, but I’m being sincere in relation to the process of secure aggregation — it’s pretty1 smart.
So.. despite my high praise for sharing model parameters, a malicious actor could technically2 reverse engineer them in some cases and reconstruct the original data points that they map to. Not good. This is where secure aggregation comes in:
** We’re going to slightly oversimplify here so get off of my case mathletes! **
Let’s simplify things by assuming 3 devices are participating in the federated learning round.
- Device 1
- Device 2
- Device 3Each device trains its model and let’s assume they produce a single model parameter each (often a model will produce many).
- Device 1 >> 0.1
- Device 2 >> 0.5
- Device 3 >> 0.9Remember, these model parameters can be reverse-engineered. So, we have to add some ~random~ noise to conceal them. Note before we add the random noise that the aggregate (average) of these model parameters equals 0.5 [(.1 + .5 + .9) / 3].
- Device 1 >> 0.1 + 0.4 - 0.2 = 0.3
- Device 2 >> 0.5 - 0.6 + 0.3 = 0.2
- Device 3 >> 0.9 + 0.2 - 0.1 = 1Now each device’s model parameters are concealed. However, if we get the average of these noise-induced model parameters we get.. 0.5! [(.3 + .2 + 1) / 3 = .5].
So, now we can give this aggregated model parameter (0.5) to the central server in a way that provides the correct value whilst masking the original model parameters. C’est cool, non?
** pip installing the-worlds-data is beginning to look a little more feasible **
Earlier we discussed that one of the issues with federated learning is heterogeneity.
For example, if two iPhones are training a keyboard prediction model and one iPhone user spends two hours texting whilst the other spends two minutes, one iPhone is going to have a disproportionate impact on the final shared model.
This problem is reasonably easy to solve for — just limit (aka “clip”) the amount of data each device is allowed to collect.
However, even if these two iPhones are limited, there’s a chance that their individual models train on data unique to them. We don’t want our final model to memorize this data. Why? Because i) it’s not reflective of all users and ii) because unique data may == private data.
Enter ✨ Differential Privacy ✨.
In ML-speak Differential Privacy is the statistical science of learning common patterns in a dataset without memorizing individual examples.
** To truly comprehend this concept took me a while — I’ll oversimplify again **
Let’s say our two iPhones are now training a facial recognition model that wants to predict when someone is smiling (like Apple’s Animojis do). Perhaps one of our iPhone users is missing a tooth, this data is both relatively rare and personal.
Our iPhones mitigate this issue by adding random “noise” to the data that they train their models on. This noise could be images of users where their teeth are sufficiently blurred, hence masking the missing tooth.
This way, the models can still learn a general pattern of a “smile” from the data without memorizing the user’s missing tooth.
Key Point: This noise does ultimately reduce the accuracy of the model. The model engineer will “tune” the degree of noise added to meet their specific privacy & accuracy goals. The variable tuned is known as epsilon (ε).
Through inserting secure aggregation and differential privacy into federated learning we get what’s known as a federated runtime.
** Now you really know how federated learning works in production! **
Federated Learning in Production
To bring this technology further to life, let’s look at some examples of Federated Learning being used in production.
Google ~created federated learning so, naturally, they use it a bunch. If you’ve ever used a Google Assistant or texted on a Google Pixel you’ve benefited from, and perhaps partaken in, federated learning.
Merck, Novartis, AstraZeneca (+ more pharma players) have begun deploying a platform dubbed “MELLODDY” to collectively train AI on datasets of patient information without having to share any proprietary data.
Owkin is using federated learning to train models on patient data from partnerships with multiple academic medical centers. They recently announced a two-part deal with Sanofi that includes a $180 million equity investment in Owkin alongside a $90 million discovery and development partnership.
** Unfortunately federated learning can’t fix the usage of long-winded accronyms in ML. **
“Why Now”
The compelling thing about privacy is that it already has product-market-fit. All else being equal, privacy > no privacy.
As Gavin Uhma points out — “in the early days of the web, HTTPS was only used for sensitive data like payments and banking” as it was performance intensive (doesn’t matter why). Sounds familiar?
Technical Detail: HTTPS stands for hyper-text-transfer-protocol-secure.
It ensures that a website is trusted (authentication) to interact with, and that data sent over a network (e.g., from your iPhone to said website) is encrypted in transit.
Advancements in the underlying HTTPS protocol have now made it ubiquitous. So, if we ascribe a similar outcome to federated learning, what are the advancements that need to occur in order for federated learning to become a standard vs. a luxury?
Firstly, if we look at what step-change event drove HTTPS to become the cool protocol on the block it was likely “HTTPS Everywhere”. A concerted effort by mainstream browsers, The Tor Project and EEF to enforce the usage of
HTTPS due to increasingly sophisticated cyberattacks.
We’re witnessing a comparable trend play out across big tech in response to GDPR/CCPA. It was Google that ~invented~ federated learning after all.
To change gears — unsurprisingly, edge devices’ computational ability needs to increase. More available compute == less training/inference latency == a better training/inference experience.
Specialized processing units, and their corresponding frameworks, such as the Apple Neural Engine → CoreML, TPU → TensorFlow Lite, and GPU → CUDA/Triton are steadily providing edge devices with this ability.
** These processing units are confusing dw — I’ll break them down simply in another post **
More compute is great and all, but if edge devices can’t practically carry out this computation due to power/memory usage concerns, we're chasing our proverbial tails.
Sakib Dadi [ a friend/subscriber :) ] recently painted a comprehensive picture of improvements panning out from a power/memory usage perspective. I highly recommend reading his piece.
To inadequately sum up, there’s a field of machine learning known as TinyML that’s pioneering a number of methods to decrease “model size” (ie how much memory your model requires). This is important, as certain model architectures such as deep neural networks require an inordinate amount of memory. Remember, memory is far more constrained within edge devices (broadly due to these devices’ physical size).
** (Read in smug voice) Good luck training a model like GPT-3 on your iPhone! **
These compute, memory, and power challenges will continue to ebb and flow. However, if mobile’s history as a compute platform tells us anything it’s that we’d be naïve to bet against it.
One step closer to pip install[ing] the-worlds-data (and a good night’s sleep!).
If you’ve come this far, thanks for reading! If you have a friend that you’d like to torture with some “light” machine learning literature, sharing this post is sincerely appreciated.
If you’re building federated learning developer tooling or solving problems with federated learning generally I’d love to talk to you / grab coffee if you’re in London >> alex@tapestry.vc
Incredibly
https://ai.googleblog.com/2022/02/federated-learning-with-formal.html