
Restate & Durable Execution
Life could do with a little more async/await.

If you enjoy these primers, I’d appreciate it if you favourite this post’s tweet or LinkedIn post to help spread the good (?) word of Why Now!
I’m at alex@tapestry.vc should you ever wish to chat, always up for saying hello.

I recently spent some time trawling through the history of The Dow Chemical Company with some friends. Niche crew, yes. The winters are cold in London.
If you think Nix or WebGPU are complicated, try getting your noggin’ around the production of bromine in 1897! A humbling experience.
Safe to say that I left this excursion with a bruised ego, but many lessons: Dow was basically a “publisher”, it’s the “chemical company’s, chemical company”, and they spend a tonne more time dissecting price pressure in their quarterly results than.. MongoDB.
The lesson that stood out though was that: product “atomicity” leads to company durability. One of Dow’s first products was bromine (silver bromide specifically), a light-sensitive compound that was used for development in analog photography.
This development process changed from the 1970s onwards with digital photography; a calamity for film-based juggernauts like Kodak, yet Dow, rather deftly, siphoned its bromine assets towards other use cases: flame retardants, tear gas, pharmaceuticals, etc.
Turns out that when the product you produce is literally an element on the periodic table, it tends to be rather versatile. It’s no secret that “platforms” are attractive for this reason: oh you like vectors? Great, check out our Atlas Vector Search product. Think stream processing is de rigueur? Atlas Stream Processing does that.
This said, Dow gave me a deeper appreciation of what it means to be a true platform. As I wrote this primer on Restate, I saw a similar opportunity.
The reason why it’s kinda difficult to understand (& hence, “in need” of a primer) is that it’s atomic. Want Lambdas represented as code? We gotcha. Need consistent multi-writes? We can do that too. It’s difficult to think of Restate as one thing, because it is in fact, everything. Let’s dig in.
Restate is an event broker “on steroids”. It:
Routes messages/invocations.
Tracks message/invocation execution.
Handles retries and recovery via persisting partial progress.
There’s a lot here, I know. We’ll break it up piece-by-piece.
Section 1 - Event Broker
Events are something that happen (e.g. a customer payment) at a point in time (e.g. 2023-01-15-14:30). Surprised? These events are represented as “logs” and collected and processed (enriched, normalised, et cetera) by titans like DDOG 0.00%↑, ESTC 0.00%↑ (via Elastic Beats or Logstash) and CFLT 0.00%↑.
Here’s a very simple log below. When these logs are sent somewhere they’re often called “messages”. At first glance, they may look a little intimidating, but study their contents and you’ll find they’re really quite intuitive.
{
"event_type": "payment_intent.succeeded",
"created_at": "2023-01-15T14:30:00Z",
"data": {
"object": "payment_intent",
"amount": 2500,
"currency": "USD",
"status": "succeeded",
}
} It’s très important to internalise that, we collect a shit-tonne (industry measure) of logs. Why? Well, we can put ‘em to work. This is the vocation of the event broker.
Brokers do this by organising these events into “topics” (think of them as folders stored on the broker). Par example, we could create a “payment_events” topic that records Stripe payments like the one above. Each time a new payment is made, the resulting log is sent to the topic:

These events aren’t providing utility yet though, are they? They’re in need of a destination (or “sink”) that consumes them. In our payments example, the sink could be a dashboard that lists new sales in real time.
What’s cool, I guess, is that brokers can also route logs from topic-to-topic. An event broker like Confluent (Kafka), may send each new log to a processing engine (i.e. software that transforms the log) like Flink, and then route the computed result to another topic.
Allow me to illustrate the above. Notice that the “payment_events” log includes a sales price (called “amount” in our log)? Each time a new log enters “payment_events”, we could send it to Flink to recalculate the median sales price of all of the logs it’s processed. We’d then send this data to the “median_sales_price” topic. Get it now?
My walkthrough hasn’t quite done the thankless role of an event broker justice however. Distributed systems are hard. What if an event fails to deliver (known as a “dead letter”) due to network issues? Or perhaps, a “sink” is overwhelmed by the deluge of `item_added_to_cart` events it’s receiving on Cyber Monday? Told ya.
I’ve adorned Confluent’s Kafka with it’s very own `whynow_cluser` which I think best illustrates how much these event brokers do. Replication (for data resiliency), data retention (for compliance), event flushing (for performance), it’s all there:
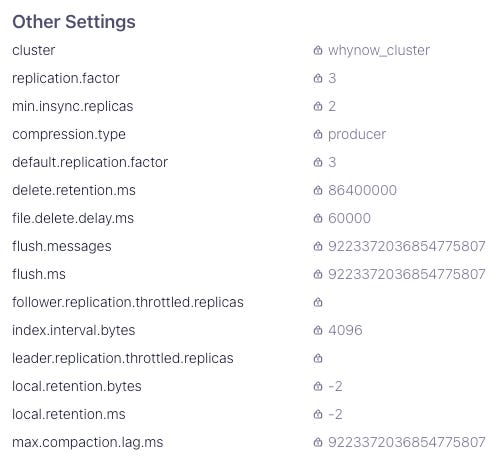
Quite a bit there, huh? In fact, event brokers are so complex, that companies can build nice businesses (15,000 customers) providing better Kafka UIs, for Confluent’s Kafka UI. You don’t see myopia like this in PaaS too often!
Cool. You’ve hopefully learned what an event broker (& Kafka) is in ~480 words. If true, I’m kinda proud of that. So where does Restate add the, eh.. steroids?
Section 2 - RPC
So far, we’ve only discussed how event brokers like Kafka transport “messages” (remember, event logs). However, what if they could also transport “procedures”?
Well, recall that our Restate description also mentioned “invocations”. An invocation is when a function (i.e. procedure) is “called” like so:
# Define a Python function
def greet(title):
return "Hello, {title}!"
# Invoke the function
greet("Why Now reader")In microservice architectures, it’s common to have a number of these functions all residing in their own servers, waiting to be called-upon. For example, a user-facing application (think a checkout screen) might call, or “invoke” a microservice (like a KYC check).
Whilst there are many ways to invoke a function remotely, this “invoking” is often done through the RPC (Remote Procedure Call) protocol.
Before we delve into RPC though, let’s first look at an alternative; partially because it’s Sunday evening and re-learning RPC requires work, but mostly because doing so will serve as a helpful contrast.
Whilst I’m not prepared to get you the data (again, Sunday), I’m willing to make a bet that plain ole HTTP requests are the most common way to invoke functions remotely (i.e. from a “client” like your web browser).
Thus, many, people write web servers that.. serve.. these HTTP requests like so:
from flask import Flask
app = Flask(__name__)
@app.route('/example', methods=['GET'])
def example_route():
return 'This is the response from the example route.'
if __name__ == '__main__':
app.run(debug=True)Looks complicated, eh! Most of this is “boiler plate” stuff so don’t fret. All that really matters is this:
@app.route('/example', methods=['GET'])
def example_route():
return 'This is the response from the example route.'Here we’re saying, when the url whynow.onrender.com/example receives a HTTP GET request, invoke the function “example_route”.
Hopefully it’s clear that we now have a way to invoke a function remotely, all we need to do is make a HTTP GET request. Great, how does one do wanna them?
Well, making GET requests is quite easy, as all you gotta do is visit (i.e. GET) the URL. Let’s do something a little more fun though. Mac users, press command + spacebar. Windows users, do better? Now, search for your “terminal” and open it.
Ok, now type: curl whynow.onrender.com/example in that fine terminal of yours. Et voilà! You’ve made a HTTP request. What’s up, h@ckɇr.
The thing is, like most general-purpose technologies, HTTP isn’t optimised for making function calls. RPC on the other hand, is.
RPC intends to make function calls appear “local”. Its goal is to make function calls look as though they’re made directly in a single file; when in reality, you’re calling functions that live in many different files, on many different servers (aka “microservices”).
Why? Well, think about it. It’s much easier to reason about functions that are “native” to the file (e.g. app.js) you’re working on. Local functions don’t need any superfluous information about handling network protocols. They’re local! There’s no need for a network to transport any data to a remote function.
Let’s make this point really hit /home. Take a look at what our app.js file (running in our browser “client”) could look like when plain ole HTTP is involved. It’s ok, your head is supposed to hurt:
const http = require('http');
// Define the server's address
const hostname = 'whynow.onrender.com';
const port = 8000;
const path = '/example';
// Create an HTTP request options object
const options = {
hostname: hostname,
port: port,
path: path,
method: 'GET',
};
// Create an HTTP request
const req = http.request(options, (res) => {
let data = '';
// Receive data from the server
res.on('data', (chunk) => {
data += chunk;
});
// Process the server's response
res.on('end', () => {
if (res.statusCode === 200) {
console.log('Data received from server:');
console.log(data);
} else {
console.error('Error:', res.statusCode);
}
});
});
// Send the HTTP GET request to the server
req.end();There’s a lot of cruft here that makes it clear that you are, in fact, not making a local function call. Perhaps it’s also now clear why we need a better way?
In RPC we use “stubs” and “skeletons” to abstract network communication details (the cruft above). Stubs are used on the client-side and look like so:
// xmlrpc is just a "library" that makes using RPC easier
const xmlrpc = require('xmlrpc');
// Create an RPC client (your "stub")
const client = xmlrpc.createClient({ host: 'whynow.onrender.com', port: 80, path: '/example' });
// Define the remote procedure and its parameters
const methodName = 'add';
const params = [3, 4];
client.methodCall(methodName, params, (error, value) => {
console.log('Result:', value);
});Again, don’t get bogged down on the code above. All you need to appreciate is that the “add” function actually lives on another file (http://whynow.onrender.com/example.)
It looks kind of “local” though, right? It’s as if we’ve just imported the “add” function as if it was a library like xmlrpc. Note that there’s also no mention of what HTTP “method” (i.e. GET) we’re availing of, status codes, or anything that suggests that we’re making a request over a network. Nice.
Before I get called out by “astute” (😉) readers, much like RPC, I have abstracted things a little here. For those that wish to go deeper, look into RPC skeletons, interface definitions and protocol buffers (Buf is cool).
Section 3 - Durable Execution
Ok, we’re kinda on a roll here. You now know what an “event broker” is, what “messages” and “invocations” are, and I’ve endowed you with a new acronym to woo folk with at dinner parties. Let’s begin to tie this all together.
Let’s revisit our definition: Restate is an event broker that routes and tracks both messages and invocations. It also handles retries and recovery via persisting partial progress.
Astute readers (the good kind 😉) might have already guessed what retries are. As we learned through studying Kafka, messages and invocations may fail for a shit-tonne (again, industry metric) of reasons. Distributed systems are hard.
It’s commonplace for developers to write logic that handles when things go awry. For example, in frontend development, it’s common to use `try` and `catch` blocks to handle network errors:
A frontend developer might `try` to fetch some data from a remote database (i.e. a network request is made), and if an error occurs, `catch` it and run some alternative logic in response. Sometimes this alternative logic is simply, trying again after a period of time has elapsed (a “retry”).
The above is a rather rudimentary example though. In reality, a single RPC call may trigger a plethora of functions across a series of microservices. One big game of distributed dominos.
Let’s look at a system that’s a little more complex, shall we? Imagine a world where I sell Why Now dad caps. When an order is placed, my system needs to:
Deduct inventory
Charge the customer's credit card
Send a confirmation email
This involves several remote services (perhaps called via RPC) and potential points of failure. For example, what if everything’s rosy for my inventory service, but a customer’s credit card on file has expired?
In this instance, I may have deducted my inventory count, despite an incomplete sale. C'est ne pas bon. To address this potential issue, I could send an error “message” (remember, a log) to an “event broker” like Restate, Temporal, Inngest, Resonate, etc., if a payment ever fails.
For this specific error, we might end the current workflow and “rollback” our inventory to its former state. Through our error message, we could then trigger a customer email informing them that they need to update their payment method. Notice how we’ve made our application more resilient, or, durable?
Event brokers that are predominately used to increase the durability of our distributed systems (again, Restate, Temporal, Inngest, Resonate) are known as “durable compute” or “durable execution” providers.
Their focus is slightly different to event brokers like Confluent and Redpanda whose primary function is real-time data transport. As a result, durable compute providers come fully-loaded with numerous helpful utilities like: retries, error handlers, timeouts, state maintenance, etc.
Cool, you’ve got retries down. Sometimes you want to pick-up where you left things off though, you want to “recover” a workflow.
In this case, perhaps we decide to keep our inventory count deducted for a period of time (i.e. we persist the “state” of our workflow). We’ll still send an email to the customer asking them to update their payment method, and, if they do so hastily, we can just resume our workflow from where it left off (known as “workflow continuation”).
Cool, that’s recovery and persisting partial progress down too. Want a dad cap?
Section 4 - Restate
Ok so: Restate is an event broker that routes and tracks both messages and invocations. It also handles retries and recovery via persisting partial progress.
Let’s delve into Restate itself now and how it actually achieves all of the above.

The image on the right is just a microservices architecture. Don’t worry about it, but note familiar terms like RPC, durable execution and retries? Nice. You’ll recognise most of the terms on the left, the one that might throw you is “async/await”.
Async/await is a common pair of keywords used in web development. In JavaScript, you place “async” in front of a function definition like so:
async function fetchData() {
try {
const response = await fetch('https://example.com/api/data');
const data = await response.json();
console.log(data);
} catch (error) {
console.error('An error occurred:', error);
}
}
fetchData();
// subsequent code blocks:
const numbers = [1, 2, 3, 4, 5];
// Use the map function to square each number
const squaredNumbers = numbers.map((num) => num * num);
// Print the squared numbers to the console
console.log("Squared numbers:", squaredNumbers);All async/await does here is enable a developer to request (often called “fetch” in web dev) some remote data, without impeding the execution of subsequent code blocks.
We’ve already learned why this matters, requesting data over networks can be unreliable. The last thing we want on our website is for the page not to fully render (i.e. subsequent code not execute) due to network issues. Async/await solves this.

To be honest, this section threw me for a spin when I first saw it. It’s actually fine though. It’s just a use cases section, chill.
1. Lambda Workflows as Code
Simply put, Lambdas are remote servers that execute some code (e.g., our inventory deduction function). Microservice architectures often chain many Lambdas together based on some “if this, then that” (i.e. event-driven) logic.
This “if this, then that” logic typically lives in a separate JSON (i.e. configuration file) to the Lambda itself. Note the “triggers” and “events” in the below JSON file:
.json
{
"FunctionName": "MyLambdaFunction",
"Runtime": "nodejs14.x",
"Handler": "index.handler",
"MemorySize": 256,
"Timeout": 10,
"Environment": {
"Variables": {
"API_KEY": "my-api-key",
"DATABASE_URL": "https://my-database-url"
}
},
"Role": "arn:aws:iam::123456789012:role/lambda-execution-role",
"Triggers": [
{
"Type": "APIGateway",
"Source": "MyApiGateway",
"Method": "POST"
},
{
"Type": "S3",
"Source": "MyS3Bucket",
"Events": ["ObjectCreated"]
}
]
}
With Restate, this configuration logic is replaced by actual code.
“Who cares?” says the, em.. gentleman.. in the back. Well, code is much more flexible than simple “key:value” data structures like JSON (e.g., you can’t “loop” in JSON).
As a result, Restate can implement more sophisticated logic like: “reliable timers & schedulers” and function suspension [1][2] vs. our lowly key:value file. My friend Jack (hello, Jack) co-authored this post on the Restate blog which further extols the benefits of this approach nicely.
2. Transactional RPC Handlers
This one should be kinda easy to grok. Recall our inventory management microservice that has two “procedures” (i.e. functions): “addInventory( )” and “deductInventory( )”.
When a client calls “deductInventory( )”, this request is initially read by an “RPC Handler” that, typically, lives in the same microservice. This RPC handler then routes the request to the exact procedure requested by the client.
Restate bestows our RPC handlers with transactional guarantees. Transactional systems are those that prioritise data consistency and integrity. For example, my inventory management service better be right, as otherwise, I might charge a customer for dad hats that I no longer have.
One way that transactional systems are achieved is via the concept of “atomicity”. This means that either my entire “transaction”: deduct inventory > charge customer’s card > send confirmation email works, or none of it does and the flow rolls-back accordingly.
As we learned earlier, Restate can persist transaction state.
3. Event Processing with Kafka
We’ve already spent time understanding how event brokers build resiliency into their message transportation (e.g., “dead letter queues”). So, let’s not rehash this too much.
Basically, Restate sits as a proxy between your event broker (Kafka) and your event consumer. It brings the qualities of durable execution to event transportation.

At this point, you likely understand all of the above? If so, sweet. This stuff ain’t easy.
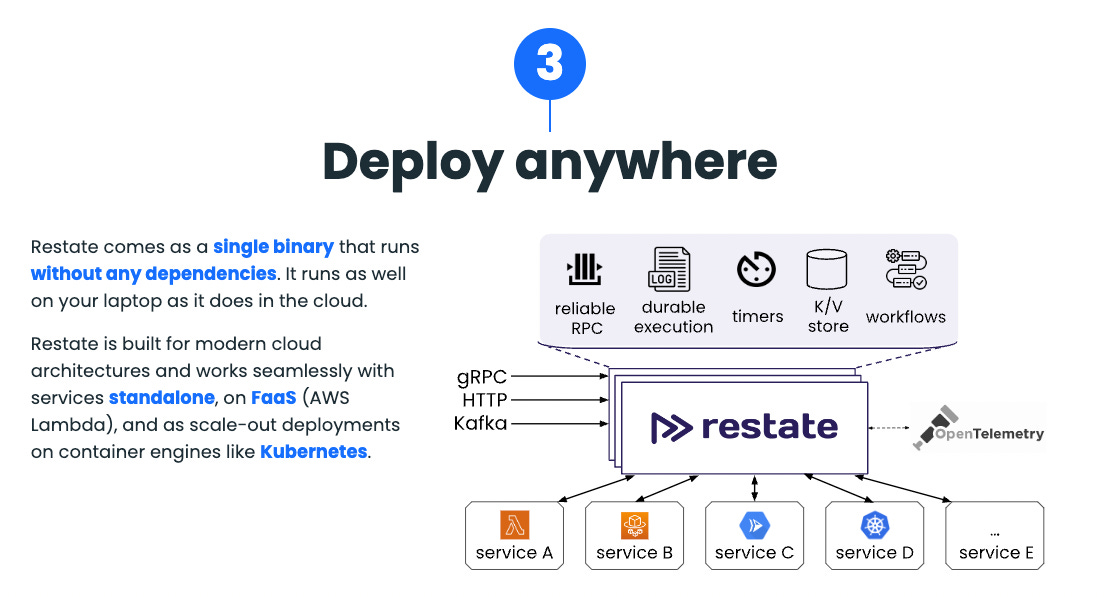
Software that comes as a “single binary”, is de rigueur in the event broker world of late. Not without good reason. Single binary software comes bundled with all of its dependencies; you can install Restate and get going.
Whereas, with Kafka for example, you need to also install the Java Runtime Environment, Kafka Command Line Tools, etc. It just takes more work.
Regarding the image on the right: gRPC (Google RPC), HTTP and Kafka are various protocols that we can use to transport messages/invocations to Restate. We have this down. OpenTelemetry I’ll deal with in a sec.

OpenTelemetry (or “OTel”) is an absolute game changer, I personally think it still doesn’t get enough airtime, but anyway.
OTel is an open source project that provides a set of APIs, libraries and agents to enable the collection of observability data (you guessed it, logs!). In microservices, “traces” document the sequence of messages/invocations that span across an application (e.g. each step in our inventory management flow).
It’s not lost on me that this primer on durable execution has been.. durably executing.. for a bit now. You all have Restate down. Sometimes one needs to `exit( )` whilst they’re ahead (sorry).
As always, there’s _so_ much more (coroutines! Warpstream! Flawless!) that I’d like to dig into here. However, the good news, readers, is that this primer is itself, a primer for what’s to come next.
I’ve wanted to put digital-pen to digital-paper on a “Every AWS Service Ever” post since the beginnings of Why Now. Post-studying the importance of “product atomicity”, now seems like no better time to do it.
10 primers down, and 11 more to come this year. Thank you for reading along, friends.